A Framework for AI Code Observability in the Enterprise
For CTOs, VPs of Engineering, and CIOs accountable for AI investment outcomes.
93.9%
frontier AI beats human developers (SWE-bench)
42%
of all code is now AI-generated
0%
of orgs can attribute AI code per agent
Section 1
Executive Summary
42% of all shipped code is now AI-generated[1]. The latest frontier models already score 93.9% on SWE-bench Verified — outperforming human developers at resolving real-world production bugs[2]. Yet virtually no organization can tell you which agent wrote which line, or whether that code survived a week in production. The gap is not the technology — it is the absence of observability.
Standard engineering intelligence platforms (DX, LinearB, Faros) measure team-level activity: cycle time, deployment frequency, PR velocity. None of them measure what fraction of a commit was authored by AI, which agent produced it, or whether that code survives in production.
Without per-line attribution, three critical questions remain unanswered:
How much of our shipped code is AI-generated?
Does that code survive — or does it generate rework?
Which vendors and teams use AI most effectively?
This paper proposes a measurement framework based on three KPIs (Adoption, Durability, Churn) and an open standard (git-ai v3.0.0) for capturing per-line AI attribution at commit time. The approach is local-first, vendor-portable, and compatible with existing engineering intelligence tools.
Section 2
The State of AI Coding in 2026
AI coding is no longer a pilot program — it is production infrastructure. 42% of all code is now AI-generated<sup>[3]</sup>. Frontier models outperform human developers on real-world bug resolution. The question is no longer "should we use AI?" but "which AI, and how do we prove it?"
93.9%
SWE-bench Verified — frontier AI vs 67–70% human baseline[4]
90%
of the Fortune 100 have deployed GitHub Copilot[5]
3–4x
productivity gains at Goldman Sachs with agentic AI coding[6]
42%
of all code is now AI-generated or AI-assisted[3]
280K
developer hours saved by Morgan Stanley's DevGen.AI in 5 months[7]
$7.6B
AI code tools market in 2025 — projected $26B by 2030[8]
The measurement gap, not a productivity gap. Accenture measured +84% successful builds and +55% shorter lead times with Copilot across 50,000 developers[5]. DORA 2025 found developers complete 21% more tasks and merge 98% more PRs — but organizational delivery metrics stayed flat. The gains are real. The ability to attribute and measure them is what's missing.
Section 2b
Enterprise Adoption by Sector
AI coding tools are no longer experimental pilots. They are production infrastructure at the world's largest organizations. 90% of the Fortune 100 have deployed GitHub Copilot alone[9]. But adoption depth varies dramatically by sector.
AI coding tool adoption by sector, 2026
Fortune 500: Universal adoption, uneven results
Accenture deployed Copilot to 50,000 developers and measured an 84% increase in successful builds, 50% faster PR merges, and 55% shorter lead times[9]. Salesforce achieved 90% adoption of Cursor across 20,000 engineers[10]. Microsoft itself adopted Claude Code across major engineering teams[10]. The scale of adoption is no longer in question — the question is whether organizations can measure the outcomes.
Banking: Billions invested, measurement is table stakes
JPMorgan Chase has 200,000+ employees on its LLM Suite with a $2B AI investment delivering 40–50% productivity increases in operations[11]. Goldman Sachs deployed Devin (autonomous AI engineer) to 12,000 developers, reporting 3–4x productivity on coding and debugging[12]. Morgan Stanley built DevGen.AI internally, processing 9 million lines of code and saving 280,000 hours across 15,000 developers in 5 months[13]. Citigroup gave 30,000 developers AI tools, measuring a 9% productivity lift[14]. Banks are not asking whether to adopt — they are asking how to audit.
Government: 3 million users, zero observability
The Pentagon launched GenAI.mil in December 2025, deploying AI to 3 million employees and contractors[15]. A separate DoD solicitation (February 2026) seeks AI coding tools for tens of thousands of developers, requiring FedRAMP High and IL5 authorization[16]. The UK government ran a formal trial across 50 organizations and measured 56 minutes saved per developer per day[17]. Gartner predicts 80% of governments will deploy AI agents by 2028[18]. The adoption is happening. The measurement infrastructure does not exist yet.
The pattern is the same across all sectors: adoption at scale, budgets in the billions, productivity claims everywhere — and almost no ability to measure what AI is actually producing in the codebase. The sector that solves measurement first gains a structural advantage in vendor management, compliance, and board reporting.
Section 2c
What the Analysts Say
Every major analyst firm has published on AI in software engineering. The consensus: adoption is inevitable, but measurement and governance are lagging dangerously behind.
Adoption trajectory and market size projections
Gartner
"By 2028, 90% of enterprise software engineers will use AI code assistants, up from less than 14% in early 2024. By 2030, 80% of organizations will evolve large teams into smaller, AI-augmented units."
Gartner Hype Cycle for AI in Software Engineering, 2025
McKinsey
"AI's impact on software engineering productivity: 20 to 45% of current annual spending. Highest performers see 16–30% team productivity improvement and 31–45% improvement in software quality."
McKinsey, 'The AI Revolution in Software Development', 2025
DORA 2025
"Developers completed 21% more tasks and merged 98% more pull requests — but organizational delivery metrics stayed flat. AI acts as an amplifier: it magnifies strengths of high performers AND dysfunctions of struggling teams."
DORA Report 2025 (Google, ~5,000 tech professionals surveyed)
BCG
"60% of organizations generate no material value from AI despite investments. Only 5% create substantial value at scale. The gap is not the technology — it is the management layer."
BCG, 'Are You Generating Value from AI?', 2025
The Productivity Paradox (DORA 2025)
Sources: DORA Report 2025, Sonar Developer Survey, ByteIota 2026 analysis
The analyst consensus is clear: AI makes individuals faster but organizations are not getting proportionally better outcomes. The missing link is measurement at the code level — not surveys, not ticket velocity, but what is actually happening in the repository. DORA themselves added a fifth metric (Rework Rate) in 2025 to address exactly this gap.
Section 2d
The Regulatory Imperative
Regulatory pressure is converging on AI-generated code from three directions: the EU AI Act, financial compliance (SOX/SOC 2), and emerging code quality mandates. Organizations that cannot identify which code was AI-generated will face audit findings, compliance gaps, and procurement blockers within 18 months.
EU AI Act enforcement timeline
EU AI Act: Transparency obligations for AI-generated content
The EU AI Act becomes fully applicable August 2, 2026. Transparency rules require providers of generative AI to ensure AI-generated content is identifiable. While coding tools are not classified as high-risk by default, code generated by AI that enters regulated products (medical devices, automotive, critical infrastructure) falls under high-risk obligations from August 2027[19]. The European Commission published its first draft Code of Practice on marking AI-generated content in December 2025.
SOX: Audit trails for AI-generated code in regulated industries
In banking, where SOX requires audit trails and PCI DSS mandates payment security validation, 29–48% of AI-generated code may contain security weaknesses[20]. Untested AI-generated code can create compliance violations with significant financial penalties. CI/CD pipelines must produce comprehensive audit trails: git commit hash, test results, approval records, deployment logs. Per-line AI attribution is the missing piece of this audit chain.
SOC 2: AI model integrity is now in scope
2026 AICPA guidance ties CC9.2 (System Operations) directly to AI model integrity: monitoring model drift, blocking prompt injection, maintaining immutable lineage of all training data and model versions[21]. Evidence quality determines 80% of audit outcomes. Continuous monitoring has replaced periodic evidence collection. Organizations using AI coding tools without attribution data have a gap in their SOC 2 evidence chain.
2025 vs 2026: The quality story has reversed — for the right models
In 2025, aggregate data painted a concerning picture: Veracode found 2.74x more vulnerabilities in AI-generated code[22], CodeRabbit reported 1.7x more issues in AI-authored PRs[23]. But those numbers measured all models — including basic autocomplete accepting suggestions without review. In April 2026, the trajectory reversed. Anthropic's Claude Mythos Preview scored 93.9% on SWE-bench Verified, dramatically outperforming human developers (67–70%) at resolving real production bugs[24]. Through Project Glasswing, the model found a 27-year-old vulnerability in OpenBSD and a 16-year-old flaw in FFmpeg that survived 5 million automated test runs[25]. Frontier AI is no longer the source of vulnerabilities — it is the tool finding them. The question is no longer whether AI produces safe code, but which AI. Regulators will not make that distinction unless organizations can prove, per commit, which agent wrote which code. Attribution is what separates "AI is a risk" from "AI is our strongest security layer."
The compliance window is closing. EU AI Act full enforcement is 4 months away (August 2026). SOC 2 already requires AI lineage evidence. SOX audit trails need to identify AI-generated code in regulated codebases. Organizations that build attribution infrastructure now have 12–18 months of evidence history when auditors arrive. Those that wait will be building evidence retroactively — and retroactive evidence is the kind auditors trust least.
Section 3
The Measurement Gap
Engineering organizations have invested in measurement platforms for over a decade. DORA metrics, SPACE framework, DXI scores. None of them measure AI authorship.
Only 16.8% of organizations track investment per AI tool versus benefit[8]. Of the remaining 83.2%, most rely on developer surveys, anecdotal feedback, or no measurement at all. When the board asks if the AI budget is paying off, the honest answer is "we don't know."
What current platforms measure
Platform category
What it tracks
Measures AI?
Engineering intelligence (DX, LinearB, Faros)
Cycle time, throughput, PR velocity, DORA
No
Code quality (SonarQube, Code Climate)
Static analysis, test coverage, complexity
No
AI gateways (LLM proxies)
Token consumption, API cost
Inputs only
Developer surveys
Self-reported satisfaction
Subjective
AI code observability (Iria Monitor, git-ai)
Per-line attribution, durability, churn
Yes
The gap is not in the data — git already stores everything needed. The gap is in capturing AI authorship at the moment of creation, before the signal disappears.
Section 4
A Framework for AI Code Observability
The framework is built on three principles:
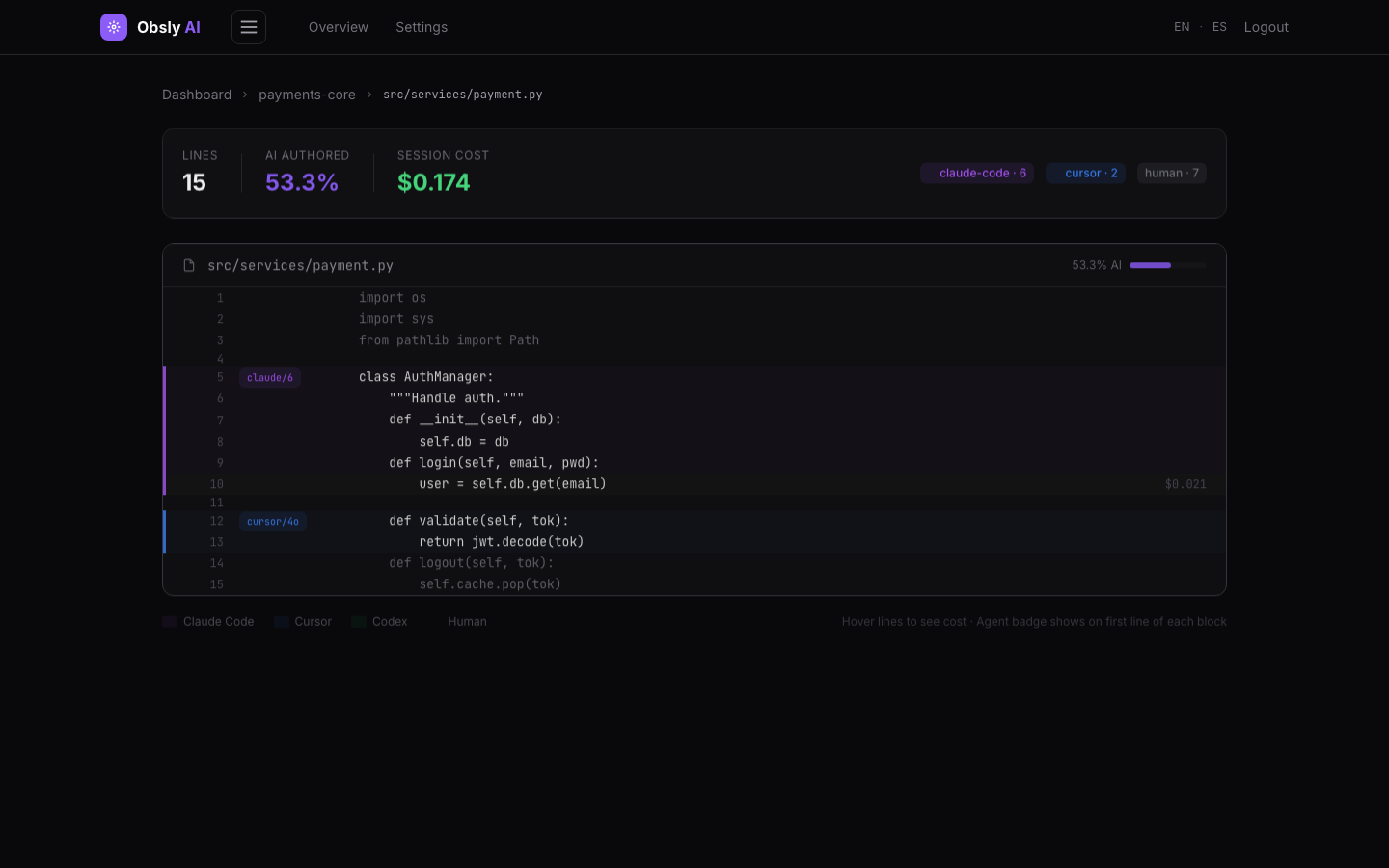
1. Capture at the source, not after the fact
AI agents (Claude Code, Cursor, Codex, Windsurf) emit PreToolUse and PostToolUse hooks when they edit files. Capturing the diff at this moment is deterministic. Detection after the fact (e.g., AI classifiers on diffs) achieves <60% accuracy.
2. Persist as git-native metadata
Attribution data is stored in refs/notes/ai as structured git notes following the open git-ai v3.0.0 standard. The data travels with the code, survives rebases via post-rewrite hooks, and is accessible to any tool that reads git.
3. Aggregate without sending source code
Only metadata leaves the developer's machine: line numbers, agent identifiers, model names, timestamps. Source code is never transmitted. Compliance reviews pass on day one.
Per-line attribution is the foundation, but the value comes from three derived metrics. These are the numbers a CTO should be able to recite for any quarter, repository, or vendor.
1
Adoption
% of code lines attributed to AI agents in a given period
Adoption alone is not a quality metric. A vendor at 80% AI may be performing better or worse than one at 30%. The value of Adoption is contextual: it sets the denominator for the other two KPIs.
Industry benchmark: Healthy teams operate between 25–40%. Above 40%, rework rates increase 20–25%[7].
2
Durability
% of AI-attributed lines still present in HEAD after N days
The single most important metric. Durability separates valuable AI code from rework. A line that survives 30 days in production was worth generating. A line rewritten the same week was not — it consumed prompt tokens, review time, and trust.
Why it matters: Two vendors at 70% Adoption can have wildly different outcomes. One at 90% Durability is delivering value. One at 55% is generating rework you pay for twice.
3
Churn
% of AI-attributed lines rewritten by humans within N days
Churn is the inverse signal of Durability and the leading indicator of trouble. High churn means humans are systematically correcting AI output. It points to wrong tool choice, wrong prompts, or wrong domain fit.
Churn(7d) = (AI lines rewritten by human within 7 days) / (AI lines added) × 100
Diagnostic value: Churn segmented by agent reveals whether the issue is the tool (Cursor 18% vs Claude 6% on the same repo) or the developer (one team 4%, another team 22% on the same agent).
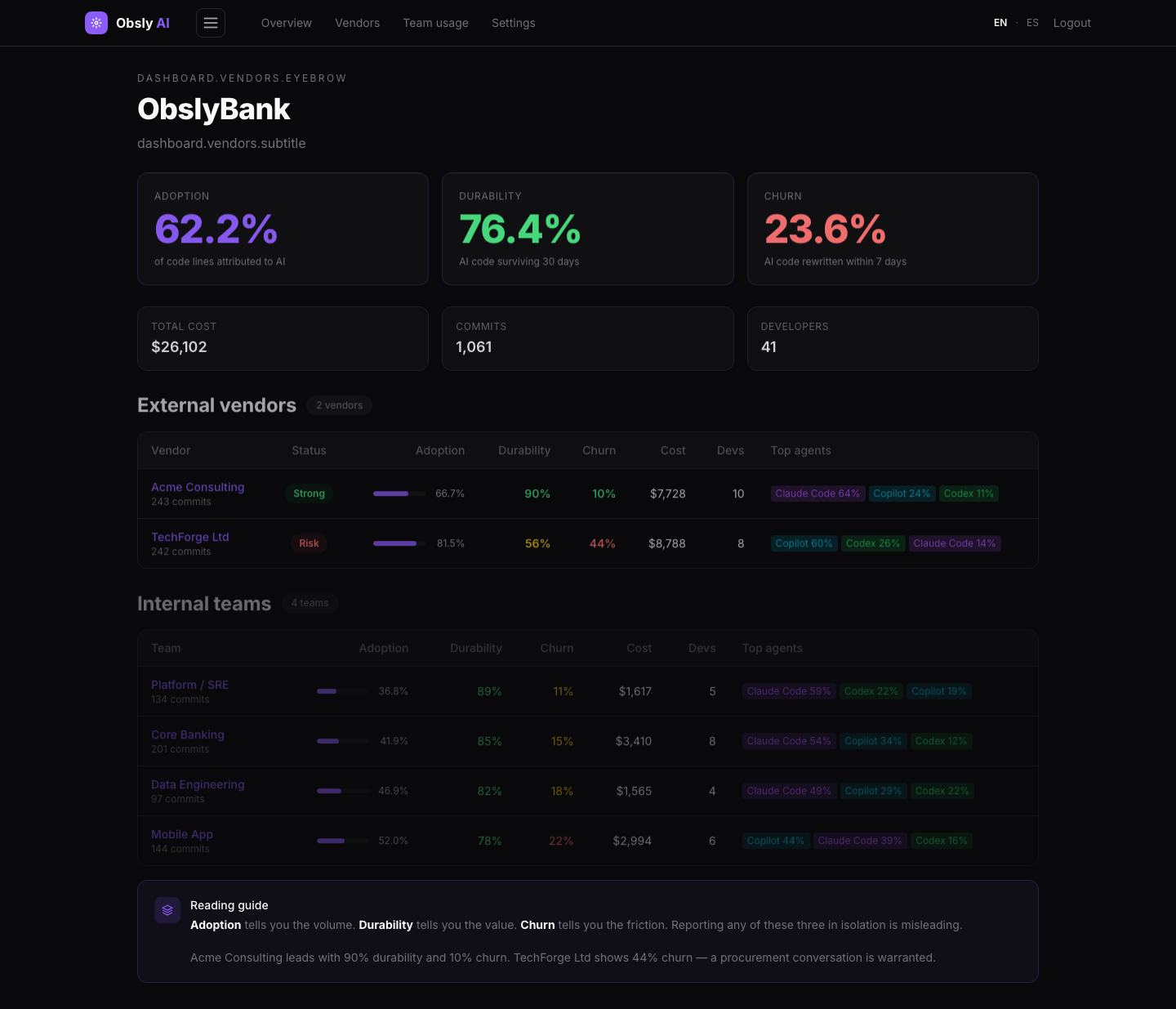
The reading order matters. Adoption tells you the volume. Durability tells you the value. Churn tells you the friction. Reporting any of these three in isolation is misleading.
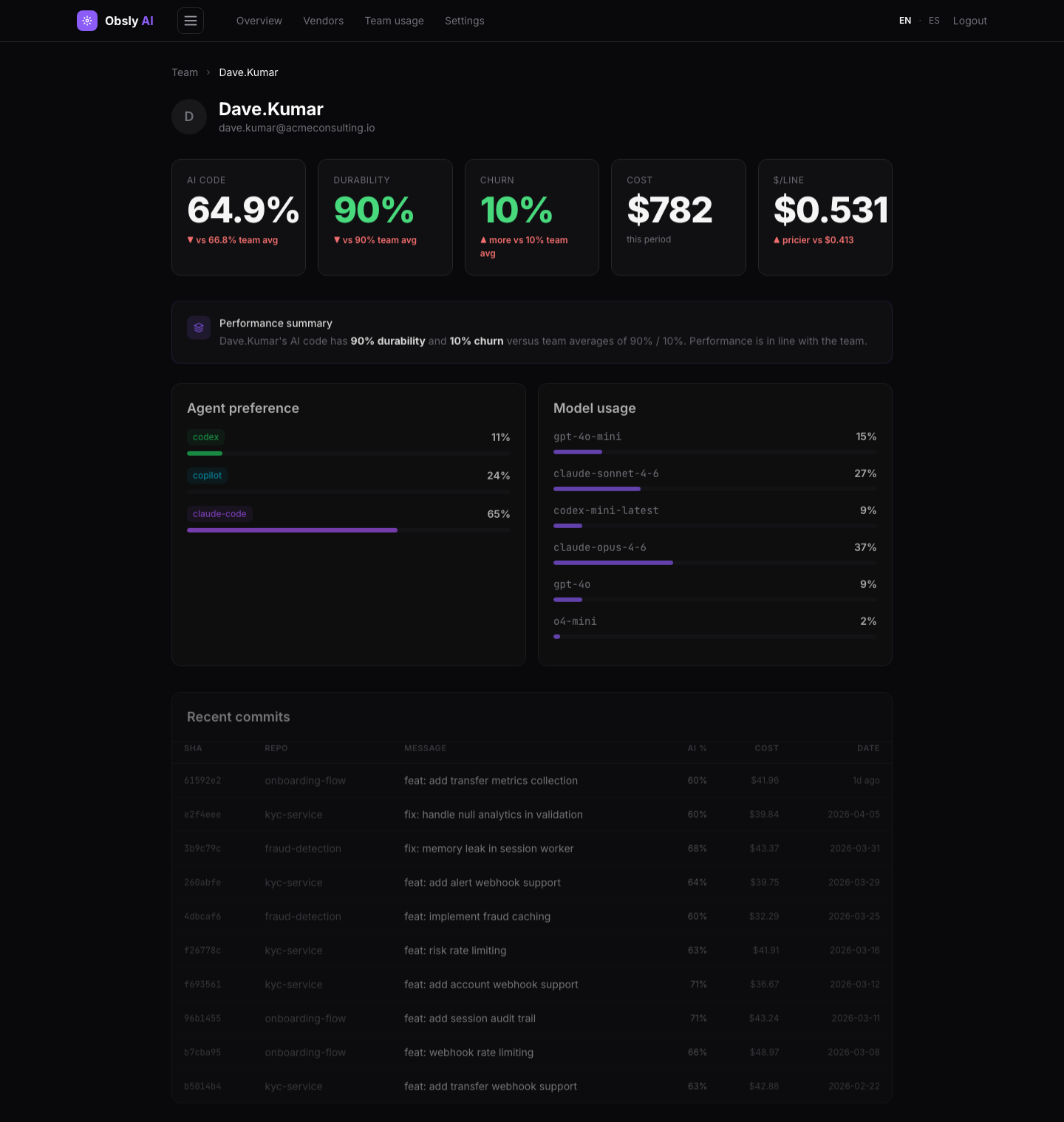
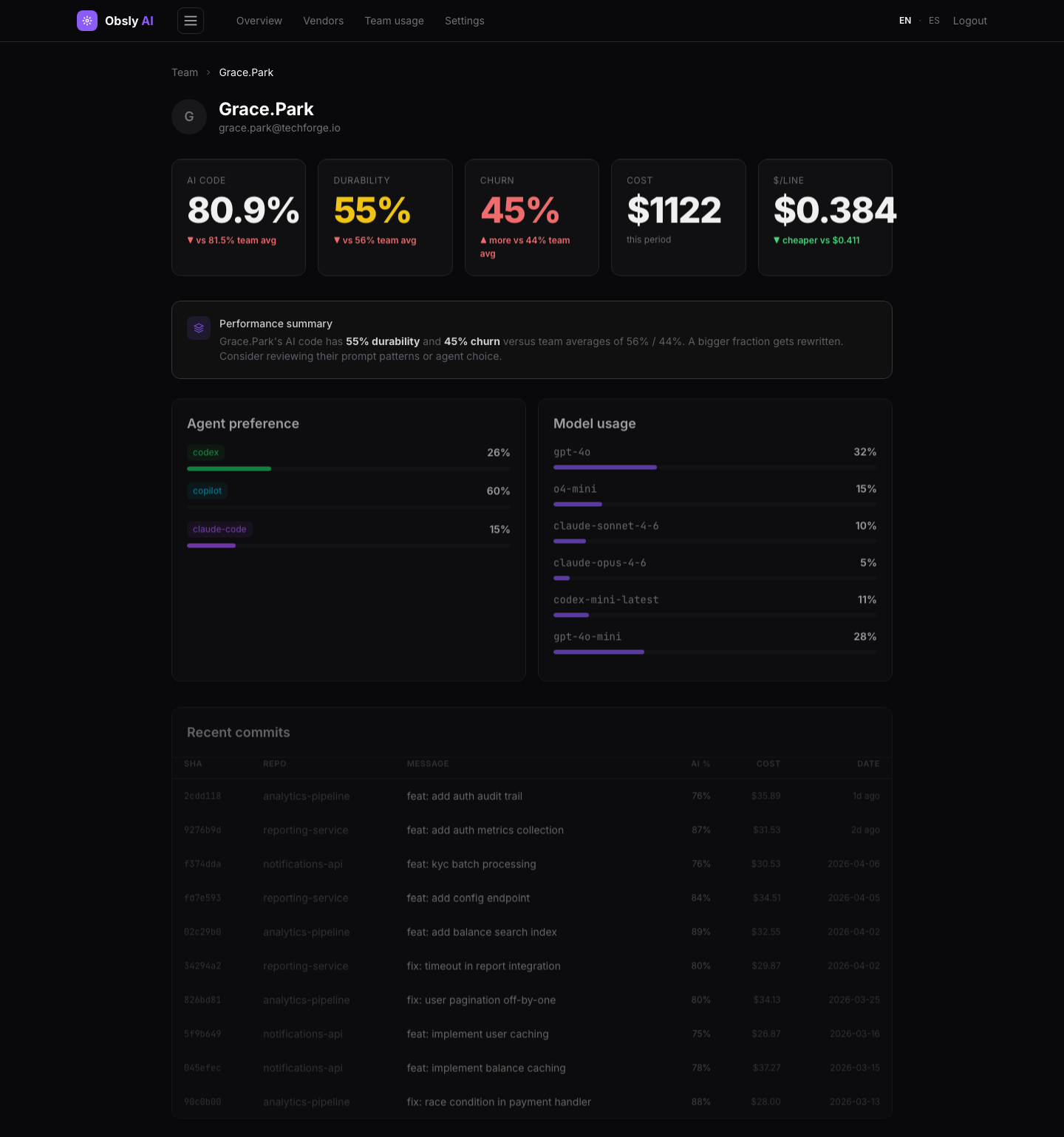
Dave Kumar (Acme) — 90% durability, 10% churnGrace Park (TechForge) — 55% durability, 45% churn
Figure 2: Same enterprise, two vendors, different outcomes (IriaBank demo data)
Section 6
Implementation Path
AI code observability does not require a new SDLC. It is a layer added to existing repositories without disturbing developer workflow.
W1
Week 1 — Pilot on a single repository
Install the CLI on three engineers' machines. Confirm hooks fire on every commit. Validate git notes appear under refs/notes/ai.
W2
Week 2 — Connect the dashboard
Install the GitHub App. Verify that pushed commits appear with their attribution. Establish baseline Adoption / Durability / Churn for the pilot repo.
W3-4
Weeks 3–4 — Roll out to one team
Onboard a complete engineering team. Compare per-developer metrics privately. Identify high-Durability and high-Churn patterns for coaching.
M2
Month 2 — Vendor visibility
For organizations with external vendors, invite them as data providers. Establish quarterly review cadence with KPIs as agenda.
Q1
Quarter 1 — Board-ready report
First quarterly report with three numbers: Adoption, Durability, Churn. Trend line. Vendor comparison. The report your CFO has been asking for.
The following scenario is illustrative and based on patterns observed in 2026 industry research. Names are anonymized.
European bank · Two-vendor procurement review
A European retail bank engages two consultancies to deliver a new mobile banking platform. Both vendors charge equivalent rates per developer. After Q1, the bank's procurement team requests AI code attribution data from both vendors.
Vendor A
Adoption68%
Durability (30d)91%
Churn (7d)4%
Vendor B
Adoption82%
Durability (30d)58%
Churn (7d)23%
The reading: Vendor B uses AI more aggressively (82% vs 68%) but produces code that gets rewritten almost a quarter of the time. The bank pays for both the original generation and the rework. Vendor A uses AI less but with substantially better outcomes.
The conversation that follows: The bank does not need to terminate Vendor B. With this data, they can ask specific questions: which agents are being used, on which file types, by which teams. The data turns a vague concern into a structured procurement discussion.
Figure 3: The vendor scorecard that drives the procurement conversation (IriaBank demo data)
Section 8
Conclusion
AI coding tools are not the problem. The absence of measurement is. Enterprise budgets have grown faster than the instruments to evaluate their return.
The framework proposed in this paper is intentionally minimal: three KPIs, one open standard, no source code transmission. It complements rather than replaces existing engineering intelligence platforms. It produces numbers a CTO can take to a board meeting and a procurement team can take to a vendor review.
The companies that adopt this layer in 2026 will be the ones that can answer, in twelve months, the only question that matters: did the AI investment pay off?
In one sentence
Without per-line attribution, AI coding investment is a faith-based exercise. With it, it becomes a managed program with KPIs the same as any other infrastructure spend.
Appendix
The Open Standard
Iria Monitor implements the git-ai v3.0.0 specification, an open standard for AI code attribution stored as git notes under refs/notes/ai. The format is human-readable, version-controlled, and portable across tools.
Organizations adopting the standard retain full data portability. If a tool change is required for any reason, the underlying attribution data is independent of the analytics platform reading it. This is the same principle that made OpenTelemetry the default for observability instrumentation: the data outlives the vendor.
[1] Sonar Developer Survey 2026 & NetCorp, AI-Generated Code Statistics 2026. 42% of all code is now AI-generated or AI-assisted.
[2] Anthropic, Claude Mythos Preview, April 2026. 93.9% SWE-bench Verified; human developer baseline 67–70%.
[3] Sonar Developer Survey 2026 & NetCorp, AI-Generated Code Statistics 2026. 42% of all code is now AI-generated or AI-assisted.
[4] Anthropic, Claude Mythos Preview, April 2026. 93.9% SWE-bench Verified; human developer baseline 67–70%. MindStudio benchmark analysis.
[5] GitHub Blog, Research: Quantifying GitHub Copilot's Impact with Accenture, 2025. 50,000-developer deployment. 90% Fortune 100 adoption per Satya Nadella, July 2025.
[6] Lucidate, Goldman Sachs Scales AI Coding to Thousands of Agents, 2026. 12,000 developers, 3–4x productivity with Devin autonomous engineer.
[7] Entrepreneur, Morgan Stanley Created an AI Tool That Saves Developers 280,000 Hours. DevGen.AI processed 9M lines of code across 15,000 developers in 5 months.
[8] Grand View Research & Precedence Research. AI code tools market: $7.65B (2025), projected $26B (2030, 27% CAGR), $91B (2035).
[9] GitHub Blog, Research: Quantifying GitHub Copilot's impact in the enterprise with Accenture, 2025. 50,000-developer deployment; 84% more successful builds.
[10] TechResearchOnline, Anthropic Enterprise AI Adoption Gains Momentum in 2026. Salesforce 90% Cursor adoption; Microsoft Claude Code adoption.
[11] AIX Network, Case Study: JPMorgan Chase AI. 200,000+ LLM Suite users, $2B investment, 40–50% productivity in operations.
[12] Lucidate, Goldman Sachs Scales AI Coding to Thousands of Agents, 2026. 12,000 developers, 3–4x productivity gains with Devin.
[13] Entrepreneur, Morgan Stanley Created an AI Tool That Saves Developers 280,000 Hours. DevGen.AI, 9M lines of code in 5 months.
[14] Banking Dive, Citi eyes AI productivity gains. 30,000 developers, 9% productivity lift via Google Cloud Vertex AI.
[15] DefenseScoop, DOD initiates large-scale rollout of commercial AI models, December 2025. GenAI.mil: 3 million users.
[16] DefenseScoop, DOD wants AI-enabled coding tools for developer workforce, February 2026. FedRAMP High + IL5 requirements.
[17] GOV.UK, AI coding assistant trial: UK public sector findings report, 2025. 50 organizations, 56 min/day saved, 58% would not go back.
[18] Gartner, 80% of Governments Will Deploy AI Agents by 2028, March 2026.
[19] European Commission, EU AI Act. Full application August 2, 2026. Transparency obligations + high-risk system compliance from August 2027.
[20] Virtuoso, Testing AI Generated Code in Regulated Industries, 2025. 29–48% AI code security weaknesses; SOX/PCI DSS implications.
[21] Baker Tilly, Evolving SOC 2 reports for AI controls, 2026. CC9.2 tied to AI model integrity; 80% of audit outcomes depend on evidence quality.
[22] Veracode, GenAI Code Security Report, 2025. AI code has 2.74x more vulnerabilities. 100+ LLMs tested across 4 languages.
[23] CodeRabbit, 2025 was the year of AI speed. 2026 will be the year of AI quality. 1.7x more issues in AI-authored PRs (470 PRs analyzed).
[24] Anthropic, Claude Mythos Preview, April 2026. 93.9% SWE-bench Verified (human baseline 67–70%). MindStudio, Claude Mythos Benchmark Results.
[25] Anthropic, Project Glasswing: Securing critical software for the AI era, April 2026. 27-year OpenBSD vulnerability, 16-year FFmpeg flaw surviving 5M test runs. $100M in credits committed.
Build your measurement layer.
Iria Monitor is the reference implementation of the framework described in this paper. Free for individual developers. Per-seat for teams. Custom for enterprise.